MCC Server Incident Summary

“So, who spilled coffee on the MCC servers on Friday 04/01?”
My name is Dana and I’m one of the engineers on the Halo Publishing Team who responded to the recent incident which affected matchmaking and custom games browser in Halo: The Master Chief Collection.
MCC’s Dedicated Server Model
In order to contextualize the details shared in this blog, here are some basic details on MCC’s server model. MCC uses dedicated servers for matchmade games and custom game browser sessions. Other game modes in MCC use peer-hosted session (where one player within the game is designated the game host).
These servers are virtual machines hosted by another team at Microsoft which serves first- and third-party Xbox studios and that team is in turn served by Azure technologies. These servers run an application which we call the Unified Dedicated Server (UDS). The UDS is effectively the server counterpart to the MCC game client and contains a wrapper which can configure and launch server versions of any of the games within MCC.
The UDS is a “trusted” authority meaning that it can’t be tampered with like MCC game clients potentially can be on PC. As such, in addition to creating a fair and reliable game experience (where all players in a game have comparable ping, the host has a stable connection, and no one has “host advantage” or “host disadvantage”), it is also a trusted source for tracking match statistics. These stats and other trusted events are used for things like calculating competitive skill ranks and progressing challenges.
From an MCC client perspective (i.e. the version of MCC that runs on your local PC or Xbox), we look at the setup of the UDS in two phases: allocation and configuration.
To allocate a dedicated server, the MCC game client makes a request to our microservice which handles some other details of the allocation on the client’s behalf. A virtual machine is allocated in the optimal region (based on ping—or manual selection in the case of the custom game browser) with sufficient machines standing by and information about the allocated machine is communicated back to the game client. From there, we enter the configuration stage where a connection between the client is established and the client begins sending configuration data for the match (which Halo game to launch, what map and game variant to load, etc.)
The Incident
On the afternoon of 04/01, our internal QA team escalated a potential matchmaking issue they were encountering on our release candidate (RC) build (the build expected to ultimately release to our players) for our upcoming MCC game update. Ensuring that this update is in good shape and able to ship by our target date has been my top priority in recent weeks, so I began investigating immediately.
After some initial investigation, the symptom became apparent. A server was being successfully allocated, but configuration was failing. It seemed surprising that this issue wouldn’t have been observed earlier in our RC testing, but as this was observed on a relatively new MCC build, the investigation was directed towards identifying what code changes since our last released game update (roughly a sixth month delta during which time numerous features were added and hundreds of bugs were fixed) could have introduced the issue.
However, it was around this time that reports started rolling in from MCC players that they were experiencing their own matchmaking issues in our production environment (the “real” environment where you play MCC as opposed to the “artificial” internal environment where we test iterative development changes for MCC). The issue we were observing in our internal environment was logically inferred to be caused by code churn from the past six months of development, so surely the production issue was not related. An issue actively impacting our players in the production environment takes priority of an internal issue, though, so our investigation retargeted that issue immediately.
It didn’t take long to confirm that the production issue was, in fact, the very same one impacting our internal RC build!
On one hand, it was a relief to confirm that the issue wasn’t something unique to our RC that would jeopardize our upcoming game update. But the fact that both builds (which were separated by six months of iterative development) were abruptly impacted in exactly the same way had concerning implications of its own. We had made two backend changes for MCC in the preceding days (in preparation for our upcoming game update), but these were logically incapable of introducing the behavior we were observing. Still, we rolled both changes back to entirely rule them out as potential causes.
Shortly after confirming this, we rolled out our first mitigation step for the issue which was to enable peer-to-peer fallback for MCC matchmaking. This allows matches where server configuration fails to fall back to a peer host (like custom games use). The peer-to-peer experience is not the ideal or intended experience and, with the lack of a trusted host we described earlier, doesn’t allow certain challenges to be progressed or skill ranks to be calculated. Still, it would at least increase matchmaking success rates and allow folks to get into matches more reliably for their Friday evening Halo-ing.
It was approaching midnight on Friday. Here’s what we knew so far...
Players were frequently failing to configure dedicated servers. From looking through logs corresponding to failures on the dedicated servers themselves, the primary configuration data was never being received from clients in the first place. Two wildly different MCC builds (one of which had been working as expected in the production environment for the past several months) were affected by the issue in exactly the same way. Recent service changes we’d made were not causal (but had been reverted just in case anyway). The primary mitigation steps we’d taken so far were enabling peer-to-peer fallback and disabling bans. Unfortunately, as we learned further into the weekend, this ban change failed to immediately take effect due to a completely unrelated issue.
On Saturday morning, now that we’d ruled out any MCC-specific changes being causal, we began engaging partner teams across Microsoft. We cast a gradually wider net as each team owning services along the path between client and server conducted their own investigation, slowly narrowing things down. On Saturday we also built a more complete understanding of the issue from a combination of data aggregation and manual reproduction of the issue aided by network traffic capture tools.
On Thin ICE
The server configuration process is conducted by way of a series of packets sent between the client and server. The client-server connection itself is negotiated via Internet Connectivity Establishment (ICE) in order to send STUN packets between them. STUN is a protocol for Session Traversal Utilities for Network Address Translator (NAT). In our case, these STUN packets are used for managing User Datagram Protocol (UDP) flow between the client and server. The connection is negotiated via binding requests which allow the client to identify the address of the server. The client will only accept solicited traffic from the server (traffic sent along an established connection), but the server can accept unsolicited traffic (allowing the client to initially establish the connection).
This process looks like an initial establishment followed by a series of configuration messages telling the server which Halo game library to launch and optionally providing map and game variant data. What we observed was that the client would send the expected initial packets, the server would receive them and send the expected packets in response, but the client never received them!
Without receiving the initial acknowledgement, the client could never move on to sending the configuration data itself. After ten seconds of not receiving acknowledgment, the client would time out which would manifest as a failure in matchmaking or the custom game browser. 30 seconds after allocation with no configuration, the UDS would shut down (putting the virtual machine back into standby, ready to be allocated again).

Parallel Wireshark captures from the client (left) and server (right) when reproducing the issue with trace view (top) and UDP stream view (bottom). IP addresses have been anonymized. The server responses (blue in the UPP stream view) are not received by the client.
Interestingly, in the cases where the client did receive the response from the server and successfully configure, it would continue to succeed any subsequent attempts to configure that virtual machine for a period of about 15 minutes. Failures were also inconsistent; a client could fail to configure a given server and then succeed on its next attempt. In the retail environment, it is highly unlikely that a client would ever make two contiguous configuration requests to the same server, but this provided some further details for our investigation.
The number of virtual machines allocated rose to higher-than-normal levels because, in most cases, they would fail configuration and clients would move onto allocate another machine and repeat the process. Meanwhile, the amount of actual UDP traffic between clients and servers fell well below normal.
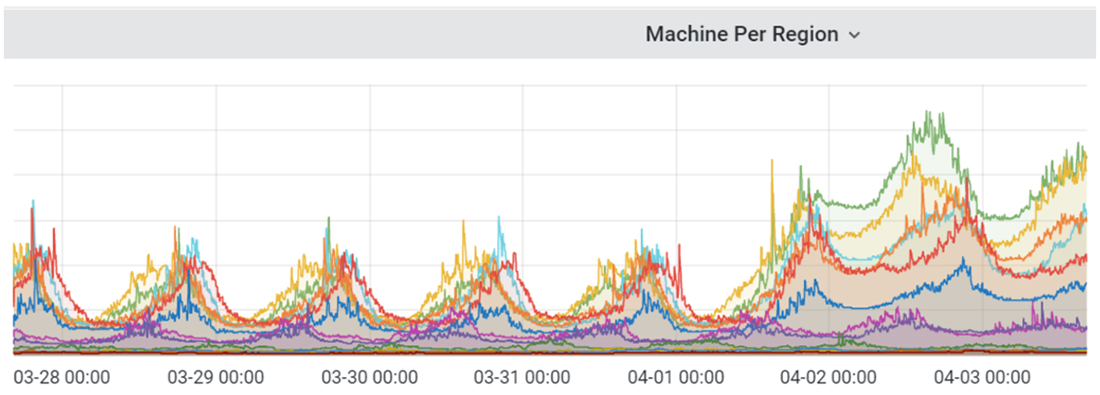
MCC dedicated server machine allocations from 03/28 through 04/03
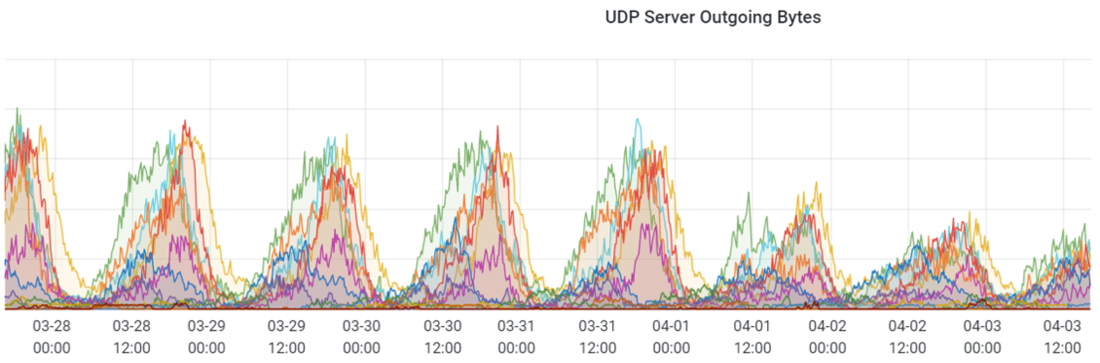
MCC dedicated server outgoing User Datagram Protocol (UDP) bytes from 03/28 through 04/03
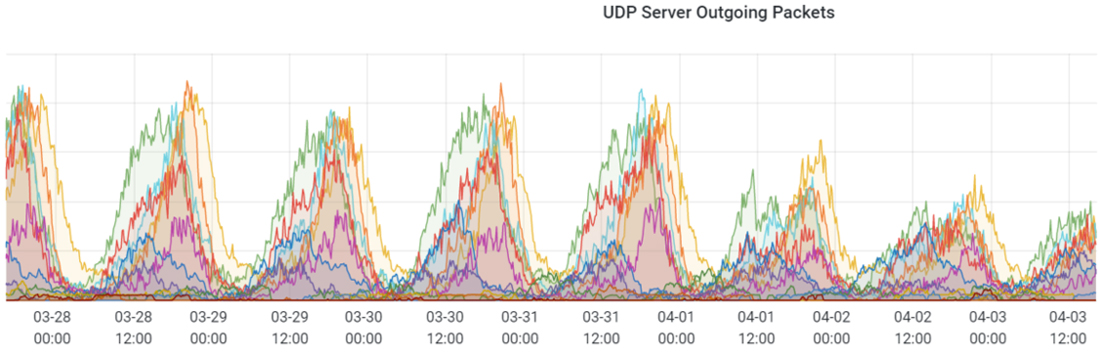
MCC dedicated server outgoing User Datagram Protocol (UDP) packets from 03/28 through 04/03
Mitigation
Thankfully, we were able to reliably reproduce the issue ourselves which allowed us to set up and capture various network diagnostics in real-time from the client and server simultaneously. This allowed us to narrow down the issue somewhat as we tracked the returning packets on their way back to the client. However, the network topology between client and server is somewhat complex and some components of it are stateful—meaning that the same inputs can result in different outputs based on surrounding factors. As a result, identifying exactly where packets were getting lost along the way was an unfortunately time-consuming process.
In parallel to this investigation, we sought to simplify our test case. MCC and the UDS are each complex applications which can introduce noise or red herrings into this kind of investigation. To combat this, we built a simple test application to replicate our traffic scenario without any other implementation details getting in the way. We found that we could consistently reproduce the issue with our simple test app if the server sent an unsolicited packet to the client (before the client established a connection). This behavior which was consistently resulting in failure would have resulted in success prior to 04/01.
Armed with this information, we were able to make a targeted change to the traffic pattern on our UDS (i.e. a change which would not require a game update for MCC). We rolled this change out in parallel to two of our development branches and began testing the fix against our live MCC build and our upcoming release candidate at the same time. With this change, we observed our server configuration success rate go from something like 25% to 100%. This testing took place on Tuesday afternoon into Wednesday morning, and we deployed our new UDS build containing the change at scale early Wednesday afternoon.
Unfortunately, players currently need to relaunch MCC to receive the new server pairing information (this is something we’re looking to improve in the future). As a result, players saw a lot of false negatives throughout Wednesday afternoon where, even if they had relaunched, someone they matched with hadn’t and they attempted to configure a server from the old deployment (without the fix). Error rates declined as more and more of the population moved up to the new server deployment.
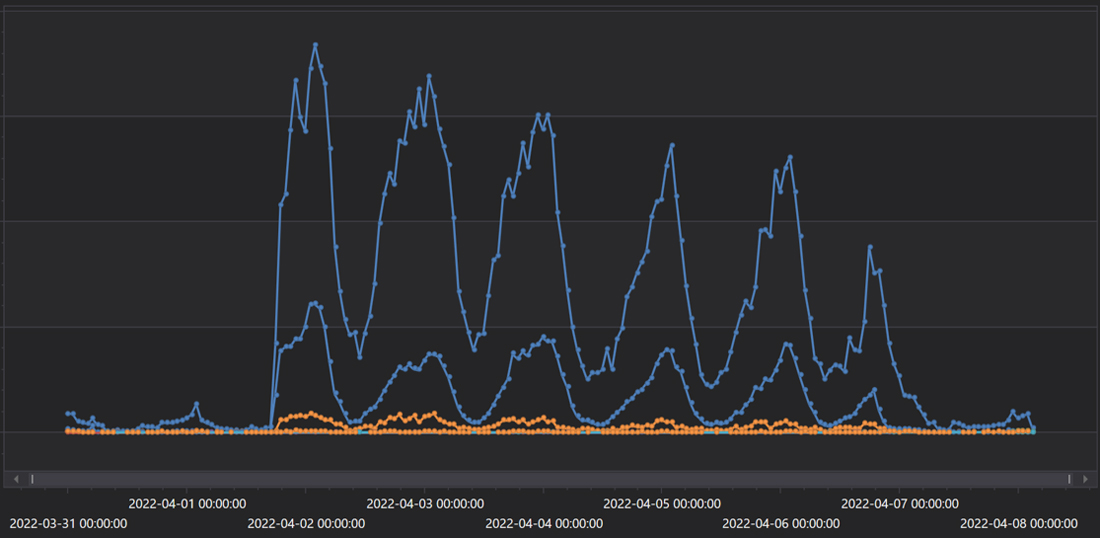
MCC dedicated server configuration and reservation failures per hour from 03/31 through 04/08
STUNning Conclusion
We finally had our fix, but what had caused this established traffic pattern (which adhered to the Internet Engineering Task Force (IETF) standard and had served us well for the past few years) to abruptly stop working? Investigation continued. Finally, it was identified that there had been some updates behind the scenes to the servers we use to relay STUN traffic as part of the ICE process which had resulted in misconfigurations.
We took other steps along the way such as adding more logging and other functionality to our UDS builds to make potential issues like this easier to diagnose in the future. We also implemented the traffic pattern change via a configurable switch (so we can reenable the old behavior at any time if needed). We were ultimately able to deploy a fix very quickly (under 24 hours from implementation to release) and without prompting a client-side MCC update (which requires certification and generally longer lead time), but the nature of the investigation to identify the issue in the first place meant that the whole process took much longer than we would’ve hoped.
Modern multiplayer games are complex and rely on a variety of technologies spanning multiple devices and networks. We’re always seeking to evolve and improve our own tech stack and how it interacts with dependent services. Thank you for joining us for this peek behind the curtain, and for your patience while we resolved the incident.